Building a Foundation in Data Science
This article illustrates the foundation of data science, covering Basic Data Concepts, Data Collection and Cleaning, and Data Visualization, with illustrations for each section.

Hi, welcome back sorry for delaying the article this time, I was attending a machine learning summer school here in Copenhagen, Denmark. I will write detail about it later but let's start from where we left last time. In this article we will talk about Foundation building in Data Science,
Data science is an interdisciplinary field that combines statistical methods, data analysis, and machine learning to extract insights and knowledge from data. At its core, data science relies on fundamental concepts such as data types, data structures, and databases. Understanding these basics is crucial for anyone looking to build a strong foundation in data science.
Data Types
Data types are the building blocks of any dataset. They define the kind of value a variable can hold and determine the operations that can be performed on that variable. Common data types include:
- Integers: Whole numbers without a fractional component, for example:
1, 5, 2, 3, 4, 100 etc. - Floats: Numbers with a fractional component, also known as floating-point numbers, for example:
1.0, 1.5, 2.9 etc. - Strings: Sequences of characters, used to represent text, for example:
Hi I am sumit. - Booleans: Logical values that can be either
TrueorFalse.
Each programming language may have its own set of data types, but the basic concepts remain the same.
Data Structures
Data structures are ways of organizing and storing data to enable efficient access and modification. Common data structures include:
- Arrays: Ordered collections of elements, typically of the same data type.
- Lists: Similar to arrays but can hold elements of different data types and often allow dynamic resizing.
- Dictionaries: Collections of key-value pairs, where each key is unique.
- Sets: Unordered collections of unique elements.
- DataFrames: Two-dimensional, table-like structures used extensively in data analysis, particularly in Python with libraries like pandas.
Choosing the right data structure is essential for optimizing the performance of data processing tasks.
Databases
Databases are organized collections of data, typically stored and accessed electronically. They provide mechanisms for storing, retrieving, and managing data efficiently. The two main types of databases are:
- Relational Databases: Use structured query language (SQL) for defining and manipulating data. They are based on a tabular structure with rows and columns (e.g., MySQL, PostgreSQL).
- NoSQL Databases: Designed for unstructured data and provide flexibility in terms of data storage and retrieval (e.g., MongoDB, Cassandra).
Understanding databases and how to interact with them is a crucial skill for data scientists, as it enables them to manage and query large datasets effectively.
Data Collection and Cleaning
Once the basics of data types, structures, and databases are understood, the next step is to gather and prepare data for analysis. This involves data collection and cleaning, which are critical for ensuring the quality and reliability of insights derived from the data.
Sources of Data
Data can come from various sources, including:
- Public Datasets: Available from government agencies, research institutions, and organizations (e.g., UCI Machine Learning Repository, Kaggle).
- APIs: Application Programming Interfaces allow access to data from web services (e.g., Twitter API, Google Maps API).
- Web Scraping: Extracting data from websites using automated tools.
- Internal Databases: Data collected and stored within an organization.
Identifying reliable and relevant data sources is the first step in the data collection process.
Data Preprocessing
Data preprocessing involves transforming raw data into a format suitable for analysis. This includes:
- Normalization: Scaling data to a standard range.
- Encoding: Converting categorical data into numerical format.
- Splitting: Dividing data into training and testing sets for model validation.
Preprocessing is essential for improving the performance of machine learning models and ensuring accurate results.
Handling Missing Values
Missing values are common in real-world datasets and can significantly impact the analysis. Strategies for handling missing values include:
- Deletion: Removing rows or columns with missing values, though this can lead to loss of information.
- Imputation: Filling missing values with statistical measures such as mean, median, or mode.
- Prediction: Using machine learning models to predict and fill in missing values.
Choosing the appropriate method depends on the nature of the data and the analysis requirements.
Data Visualization
Data visualization is the process of representing data graphically to make insights more accessible and understandable. Effective visualization can highlight patterns, trends, and outliers that might be missed in raw data.
Tools for Data Visualization
Several tools are available for creating data visualizations, each with its strengths:
- Matplotlib: A widely-used Python library for creating static, interactive, and animated visualizations. It provides a high degree of customization for plots.
- Seaborn: Built on top of Matplotlib, Seaborn provides a high-level interface for drawing attractive and informative statistical graphics. It simplifies complex visualizations like heatmaps and pair plots.
- Tableau: A powerful and user-friendly data visualization tool that allows users to create interactive and shareable dashboards. It supports a wide range of data sources and provides drag-and-drop functionality for ease of use.
- PowerBI: PowerBI is mostly used in industry and gradually gaining traction from many eyes, it is simple and also you can run python scripts and libraries mentioned above (Matplotlib, Seaborn) on it that gives it edge over others.
Mastering these tools enables data scientists to communicate their findings effectively and support data-driven decision-making.
Machine Learning
Machine learning is an integral and crucial part of data science these days. I've met many industry professionals who frequently use machine learning models in their daily work, regardless of their department. One fascinating anthropologist told me that she uses machine learning to understand the factors affecting their Net Promoter Score (NPS), analyzing the percentage impact of different parameters. I think Currently, there are two types of models that people use frequently:
Light model
Generally people who are starting deep learning or industry folks working in another department except AI, uses them heavily in their day to day tasks. This incudes general Machine Learning models and some simple deep learning models i.e. Bert for sentiment analysis (pretrained) from Hugingface. In simple words any model you can run on CPU (without having any heating issues 😉) can be classified as light model.
Heavy model
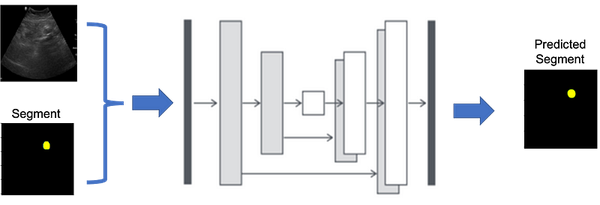
Heavy models typically require GPUs for running or training. Generally, people working in core machine learning or applied machine learning use these models to solve various problems. Being a Medical image Analysis practitioner I also use some of these models (SAM, DINOV2, CNN based models.. etc) to predict diseases using CT, ultrasound, and MRI scans.
Conclusion
Building a foundation in data science requires a solid understanding of basic data concepts, effective data collection and cleaning techniques, and proficiency in data visualization tools. By mastering these fundamentals, aspiring data scientists can develop the skills necessary to analyze and interpret data, uncover insights, and contribute to data-driven solutions across various domains.