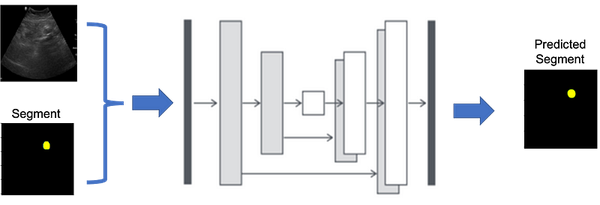
Combining YOLOv8 and SAM for Image Segmentation
Combining YOLO and SAM for better segmentation results


A few months ago, I was thinking about the most significant challenges in segmentation. I identified two of them as the most crucial. The first one is limited availability of labeled data, and the second one is environmental concerns, specifically the substantial computing power required for training large models, which has a significant environmental cost.
The first problem encompasses two major challenges:
Challenge 1: Unlabeled Medical Data: Imagine a library filled with thousands of books, but none with titles or summaries. This is the reality in medical imaging today — an abundance of data, but most of it unlabeled. This lack of labels severely hampers the potential insights we could gain from this treasure trove of information.
Challenge 2: Scarcity of Medical Experts for Annotation: Our second hurdle is the scarcity of medical experts to annotate these images. These skilled professionals are already heavily engaged in life-saving clinical work, making them scarcely available for the meticulous task of data labelling, an essential step in training our AI models. Specially in case of segmentation task where we specifically require expert radiologists or doctors.
Solution: To address these problems, we have combined two of the most powerful segmentation models: YOLOv8 and SAM (Segment Anything Model). This combination effectively resolves all three challenges. How does it work? Let’s delve into it:
After training, YOLOv8 can generate both boundary boxes and segmentation masks. On the other hand, SAM can produce masks for every object it recognizes in the input image, and one notable advantage of SAM is that it does not require retraining. However, to generate masks for specific objects using SAM, we need to guide SAM towards those objects, and this is achieved through boundary boxes referred to as prompts.
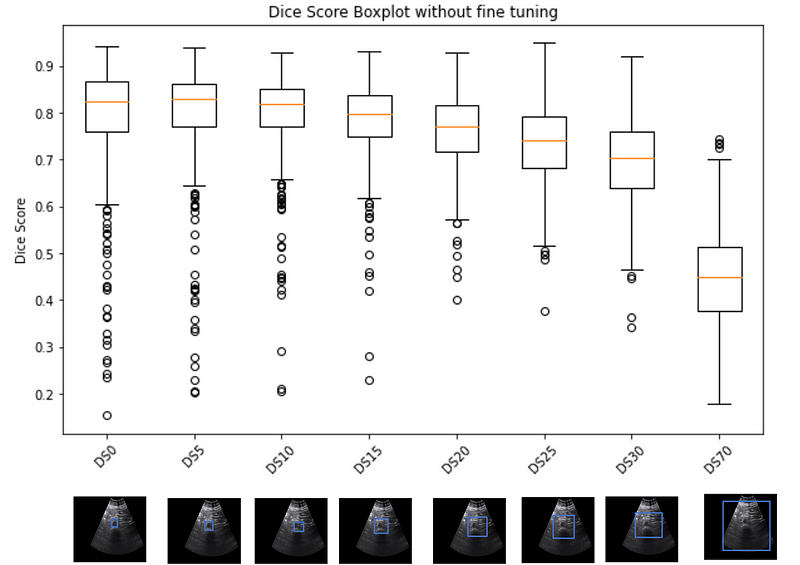
SAM possesses another remarkable capability — it can handle ambiguity in prompts (boundary boxes) exceptionally well. Even if the boundary box is slightly larger or smaller than the actual size, it won’t significantly impact the Dice score. As illustrated in Figure 1, where the X-axis represents the size difference of the boundary box from the actual size (DS0: perfect fit, DS5: boundary box is 5 pixels bigger, and so on), the Y-axis represents the Dice Score.
Experiments:
In order to show its efficiency, we experimented with three modalities: CT, Ultrasound and X-ray.
Methodology:
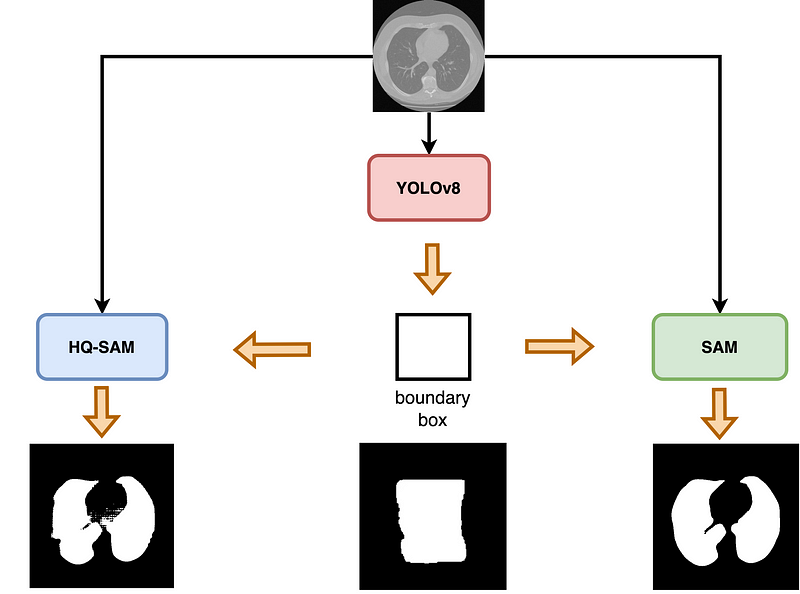
In this work we used three models: YOLOv8, SAM and HQ-SAM. HQ-SAM is just an extension of HQ-SAM there is no major difference. As we show in figure 1, SAM can handle ambiguity in prompt very well. So we first trained our YOLOv8 model with just 100 images and masks, this will allow YOLOv8 to generate very bad masks (as shown in figure 2) but approximate boundary boxes and SAM can handle this very approximation very well. From approximation the output of SAM (or HQ-SAM) is really great as we see here in figure 2.
Results:
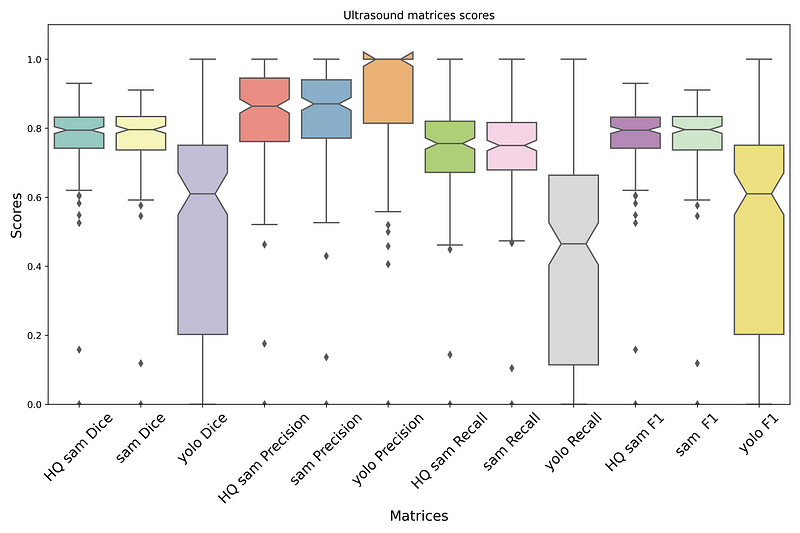
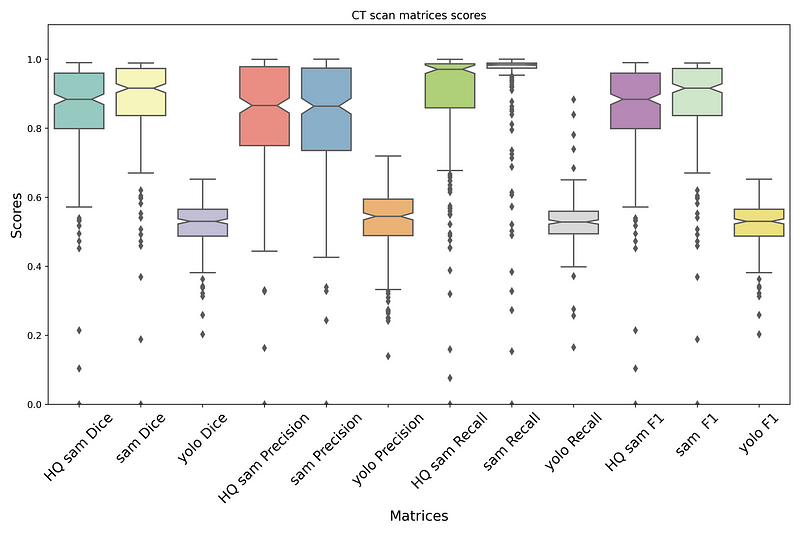
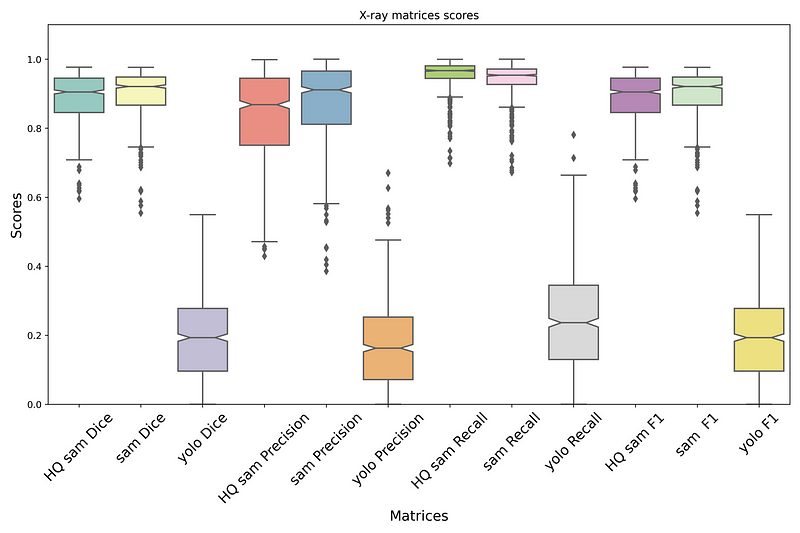
The results of the method on Ultrasound, X-ray, and CT scan can be observed in Figures 3, 4, and 5. In these figures, you can examine the Dice Score, Precision, Recall, and F1 score for all three models: HQ SAM, SAM, and YOLOv8. As evident from the data, when compared to YOLOv8, both SAM and HQ SAM (enhanced by YOLOv8) performed better in all metrics, including Dice Score, Precision, Recall, and F1 score.
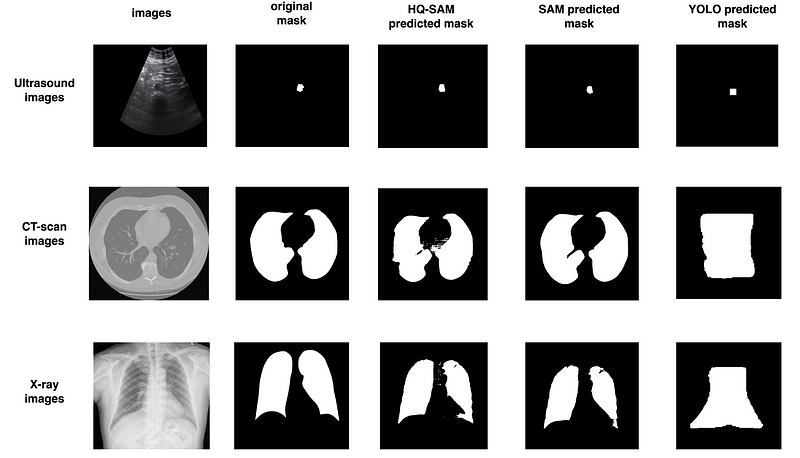
As you can observe in Figure 6, the predicted masks produced by SAM and HQ SAM outperform those generated by YOLOv8 across all types of images (CT, X-ray, and CT-scan).
So what do you say about it? Pretty cool right and finally second problem the environmental problem: we are already solving it by training on just 100 images and masks. I also have made an app on huggingface so please click below and try it by yourself. And one more thing, I presented this paper at ICCV workshop last year (2023).

Happy learning 😃