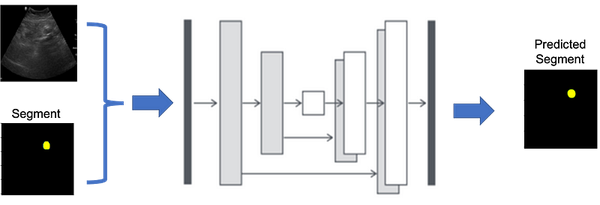
Reproducible Machine Learning
In the dynamic realm of machine learning, reproducibility is vital for ensuring consistent, trustworthy results. This guide delves into reproducible machine learning, emphasizing the importance of replicating outcomes through precise data, code, and environment management.

In the rapidly evolving field of machine learning (ML), the reproducibility of results is crucial. Reproducibility ensures that an experiment or a model can be recreated under the same conditions, leading to consistent results. This consistency builds trust in the findings, facilitates peer review, and accelerates scientific progress. Here’s a comprehensive guide on what reproducible machine learning is and how to achieve it.
What is Reproducible Machine Learning?
Reproducible machine learning refers to the ability to replicate the outcomes of an ML experiment by using the same data, code, and environment. It implies that someone else, or even the original researcher at a later time, can reproduce the same results using the provided resources and documentation. Reproducibility is different from replicability, which means obtaining consistent results using new data but the same methodology.
Why is Reproducibility Important?
- Validation: Reproducibility allows other researchers to validate findings and ensure the results are accurate and not a product of random chance or specific configurations.
- Transparency: It promotes transparency in research, making it clear how results were obtained.
- Progress: Facilitates scientific progress by enabling researchers to build upon each other’s work without having to start from scratch.
- Error Detection: Helps in identifying errors or biases in the model, code, or data.
- Collaboration: Makes collaboration easier by providing a clear and consistent framework for how experiments were conducted.
How to Achieve Reproducible Machine Learning
Achieving reproducibility involves several best practices spanning from data management to coding practices and documentation.
- Data Management
- Data Versioning: Use tools like DVC (Data Version Control) to version control datasets. This ensures that the exact version of the dataset used in experiments is recorded and can be accessed later.
- Raw Data Preservation: Always preserve the raw data. Any preprocessing steps should be documented and ideally scripted.
- Data Provenance: Maintain a record of data sources and any changes made over time.
- Code Management
- Version Control: Use version control systems like Git to manage changes in your codebase. Tools like GitHub, GitLab, or Bitbucket can facilitate collaboration and code review.
- Environment Management: Use environment management tools like Conda or virtual environments to ensure that dependencies and libraries remain consistent across different runs. Docker can be used to containerize the entire environment.
- Modular Code: Write modular and clean code. Functions and classes should be used to encapsulate different parts of the pipeline, making it easier to understand and reuse.
- Experiment Tracking
- Logging: Use experiment tracking tools such as MLflow, Weights & Biases, or Neptune.ai to log experiments, hyperparameters, metrics, and outputs. This helps in comparing different runs and understanding the impact of changes.
- Random Seeds: Set random seeds for all stochastic processes (e.g., data shuffling, model initialization) to ensure consistency across runs.
- Documentation
- Comprehensive Documentation: Document every step of the process, from data collection and preprocessing to model training and evaluation. This should include explanations of choices made, hyperparameters used, and any assumptions.
- ReadMe Files: Maintain a README file in your project repository that explains how to set up the environment, run the code, and reproduce the results.
- Testing
- Unit Tests: Write unit tests for critical parts of your code to ensure that changes do not break existing functionality.
- Integration Tests: Ensure that different components of your ML pipeline work together as expected.
- Open Science
- Open Source: Where possible, make your code and data publicly available. Use platforms like GitHub for code and Zenodo for datasets to share your work with the broader community.
- Preprints and Publications: Publish your findings in preprint servers and peer-reviewed journals. Include detailed methodology sections to facilitate reproducibility.
Tools and Frameworks
- DVC (Data Version Control): For versioning datasets and machine learning models.
- Git: For version control of code.
- Conda/Docker: For environment management.
- MLflow, Weights & Biases, Neptune.ai: For experiment tracking.
- Jupyter Notebooks: For creating and sharing documents that contain live code, equations, visualizations, and narrative text.
Conclusion
Reproducibility in machine learning is not just a technical challenge but a fundamental requirement for scientific integrity and progress. By adhering to best practices in data management, coding, documentation, and testing, researchers and practitioners can ensure that their work is reliable, trustworthy, and valuable to the broader community. Reproducibility should be considered at every stage of the ML pipeline to foster an open, collaborative, and progressive research environment.