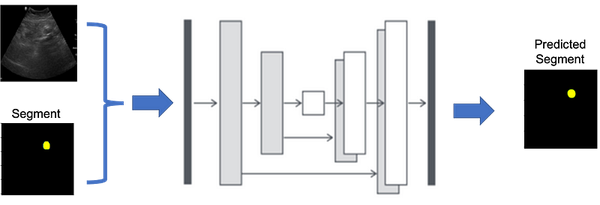
‘RuntimeError: CUDA out of memory’, problem solved using ‘Gradient Accumulation’
Last year, I was working on BRATs-23 segmentation challenge when I realized I can’t increase the batch size more than ‘one’ because…


Last year, I was working on BRATs-23 segmentation challenge when I realized I can’t increase the batch size more than ‘one’ because whenever I try to do this I always used to get this error:
RuntimeError: CUDA out of memory. Tried to allocate 576.00 MiB
(GPU 0; 39.42 GiB total capacity; 20.89 GiB already allocated;
403.69 MiB free; 20.90 GiB reserved in total by PyTorch)
If reserved memory is >> allocated memory try setting max_split_size_mb
to avoid fragmentation. See documentation for Memory Management and
PYTORCH_CUDA_ALLOC_CONFThe primary factor is the large size of medical images; typically, an MRI image is around 20+ MB (megabytes) or more, depending on its resolution. This led me to discover Gradient Accumulation in a Kaggle notebook (I don’t know the original author). Let’s outline our plan of attack to learn about it:
- Introduction
- How it works in practice
- Implementation of ‘Gradient Accumulation’ in trainer class.
- Results
- Advantages of Gradient Accumulation
Introduction
Gradient accumulation is a useful technique to effectively train models with large batch sizes even when you’re limited by GPU memory. It allows you to simulate the training with a larger batch size than you can physically fit into your GPU memory by splitting the large batch into smaller sub-batches and accumulating the gradients over these sub-batches. This way, you can achieve the regularization effects and convergence benefits of training with large batch sizes without needing the physical memory to accommodate the entire batch at once.
How it works in practice:
1. Split the Large Batch into Smaller Sub-batches: Divide your large batch into smaller sub-batches that fit into your GPU memory.
2. Forward Pass: For each sub-batch, perform a forward pass through the network to compute the loss.
3. Backward Pass: Perform a backward pass to compute the gradients for each sub-batch. However, instead of updating the model parameters immediately after each sub-batch, you temporarily store these gradients.
4. Accumulate Gradients: Add up the gradients from each sub-batch. This accumulation step is key because it effectively simulates the gradient that would have been obtained if the entire large batch had been processed at once.
5. Parameter Update: After processing all the sub-batches and accumulating their gradients, update the model parameters using the accumulated gradients. This step is typically done once per simulated large batch.
6. Repeat: Repeat the process for the next set of sub-batches until you’ve processed your entire dataset.
Implementation of ‘Gradient Accumulation’ in trainer class:
In this class below please take a look at ‘for’ loop in ‘_do_epoch’ you will notice above steps.
# This class `Trainer` is a factory for the training process of a neural network.
# It initializes necessary components for training, conducts training epochs, and provides methods for saving training history.
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.optim.lr_scheduler import ReduceLROnPlateau
from utils import get_dataloader, Meter
import time
import matplotlib.pyplot as plt
import pandas as pd
class Trainer:
"""
Factory for training process.
Args:
display_plot: if True - plot train history after each epoch.
net: neural network for mask prediction.
criterion: factory for calculating objective loss.
optimizer: optimizer for weights updating.
phases: list with train and validation phases.
dataloaders: dict with data loaders for train and val phases.
path_to_csv: path to csv file.
meter: factory for storing and updating metrics.
batch_size: data batch size for one step weights updating.
num_epochs: num weights updation for all data.
accumulation_steps: the number of steps after which the optimization step can be taken.
lr: learning rate for optimizer.
scheduler: scheduler for controlling learning rate.
losses: dict for storing lists with losses for each phase.
jaccard_scores: dict for storing lists with Jaccard scores for each phase.
dice_scores: dict for storing lists with Dice scores for each phase.
"""
def __init__(self,
net: nn.Module,
dataset: torch.utils.data.Dataset,
criterion: nn.Module,
lr: float,
accumulation_steps: int,
batch_size: int,
fold: int,
num_epochs: int,
path_to_csv: str,
display_plot: bool = True,
):
"""Initialization."""
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
print("device:", self.device)
self.display_plot = display_plot
self.net = net
self.net = self.net.to(self.device)
self.criterion = criterion
self.optimizer = Adam(self.net.parameters(), lr=lr)
self.scheduler = ReduceLROnPlateau(self.optimizer, mode="min",
patience=2, verbose=True)
self.accumulation_steps = accumulation_steps // batch_size
self.phases = ["train", "val"]
self.num_epochs = num_epochs
self.dataloaders = {
phase: get_dataloader(
dataset=dataset,
path_to_csv=path_to_csv,
phase=phase,
fold=fold,
batch_size=batch_size,
num_workers=4
)
for phase in self.phases
}
self.best_loss = float("inf")
self.losses = {phase: [] for phase in self.phases}
self.dice_scores = {phase: [] for phase in self.phases}
self.jaccard_scores = {phase: [] for phase in self.phases}
def _compute_loss_and_outputs(self,
images: torch.Tensor,
targets: torch.Tensor):
images = images.to(self.device)
targets = targets.to(self.device)
logits = self.net(images)
loss = self.criterion(logits, targets)
return loss, logits
def _do_epoch(self, epoch: int, phase: str):
print(f"{phase} epoch: {epoch} | time: {time.strftime('%H:%M:%S')}")
self.net.train() if phase == "train" else self.net.eval()
meter = Meter()
dataloader = self.dataloaders[phase]
total_batches = len(dataloader)
running_loss = 0.0
self.optimizer.zero_grad()
for itr, data_batch in enumerate(dataloader):
images, targets = data_batch['image'], data_batch['mask']
loss, logits = self._compute_loss_and_outputs(images, targets)
loss = loss / self.accumulation_steps
if phase == "train":
loss.backward()
if (itr + 1) % self.accumulation_steps == 0:
self.optimizer.step()
self.optimizer.zero_grad()
running_loss += loss.item()
meter.update(logits.detach().cpu(),
targets.detach().cpu()
)
epoch_loss = (running_loss * self.accumulation_steps) / total_batches
epoch_dice, epoch_iou = meter.get_metrics()
self.losses[phase].append(epoch_loss)
self.dice_scores[phase].append(epoch_dice)
self.jaccard_scores[phase].append(epoch_iou)
print('loss:', epoch_loss, 'Dice score: ', epoch_dice, 'IOU: ', epoch_iou)
return epoch_loss
def run(self):
for epoch in range(self.num_epochs):
print('Number of Epoch: ', epoch)
self._do_epoch(epoch, "train")
with torch.no_grad():
val_loss = self._do_epoch(epoch, "val")
self.scheduler.step(val_loss)
if self.display_plot:
self._plot_train_history()
if val_loss < self.best_loss:
print(f"\n{'#' * 20}\nSaved new checkpoint\n{'#' * 20}\n")
self.best_loss = val_loss
torch.save(self.net.state_dict(), "best_model.pth")
print()
self._save_train_history()
def _plot_train_history(self):
data = [self.losses, self.dice_scores, self.jaccard_scores]
colors = ['deepskyblue', "crimson"]
labels = [
f"""
train loss {self.losses['train'][-1]}
val loss {self.losses['val'][-1]}
""",
f"""
train dice score {self.dice_scores['train'][-1]}
val dice score {self.dice_scores['val'][-1]}
""",
f"""
train jaccard score {self.jaccard_scores['train'][-1]}
val jaccard score {self.jaccard_scores['val'][-1]}
""",
]
with plt.style.context("seaborn-dark-palette"):
fig, axes = plt.subplots(3, 1, figsize=(8, 10))
for i, ax in enumerate(axes):
ax.plot(data[i]['val'], c=colors[0], label="val")
ax.plot(data[i]['train'], c=colors[-1], label="train")
ax.set_title(labels[i])
ax.legend(loc="upper right")
plt.tight_layout()
plt.show()
def load_predtrain_model(self,
state_path: str):
self.net.load_state_dict(torch.load(state_path))
print("Pretrained model loaded")
def _save_train_history(self):
"""writing model weights and training logs to files."""
torch.save(self.net.state_dict(),
f"last_epoch_model.pth")
logs_ = [self.losses, self.dice_scores, self.jaccard_scores]
print('logs: ', self.losses, 'Dice: ', self.dice_scores, 'IOU: ', self.jaccard_scores)
log_names_ = ["_loss", "_dice", "_jaccard"]
logs = [logs_[i][key] for i in list(range(len(logs_)))
for key in logs_[i]]
log_names = [key + log_names_[i]
for i in list(range(len(logs_)))
for key in logs_[i]
]
pd.DataFrame(
dict(zip(log_names, logs))
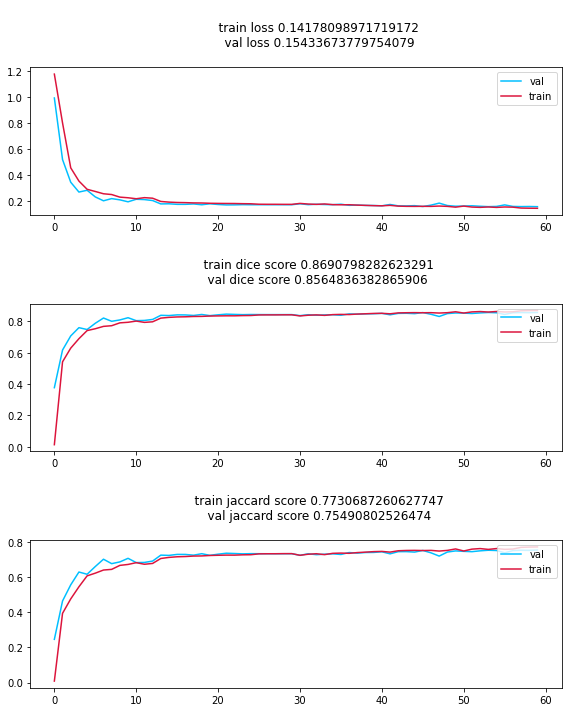
).to_csv("train_log.csv", index=False)Results
Advantages of Gradient Accumulation:
- Memory Efficiency: Allows training with large batch sizes without being constrained by GPU memory limits.
- Improved Training Dynamics: Larger effective batch sizes can lead to smoother optimization landscapes and better generalization in some cases.
- Flexibility: Offers the flexibility to adjust the effective batch size without changing the hardware setup.
That’s it !! congratulations we did it 😃
Here is the kaggle notebook for complete work: https://www.kaggle.com/code/nurislamsowmik/brats20-3dunet-3dautoencoder-sowmik